December 2024:
Accepted summer internship offer at Google Deepmind, beginning June 2025.
December 2024:
We released our first demo at WorldLabs.
Industry experience
June 2025 - December 2025:Google Research. Student researcher.
June 2024–June 2025:World Labs. Pretraining research, base models.
September 2022–June 2024:Google DeepMind / Google Research. Student researcher.
October 2020–August 2022:Google Research. AI Resident.
Research
My research area is computer vision. My overall goal is to build visual intelligence. I am currently exploring several research areas:
Visual tokenization technique to compress visual data effectively and learn interesting representations, such as in FlowMo and VLIC.
Adding 3D controls to large generative models such as in my CVPR 2024 paper ZeroNVS, or my ICCV 2023 first-authored Best Paper Finalist, VQ3D.
Visual robustness techniques such as my CVPR 2022 co-first-authored Best Paper Finalist, Pyramid Adversarial Training.
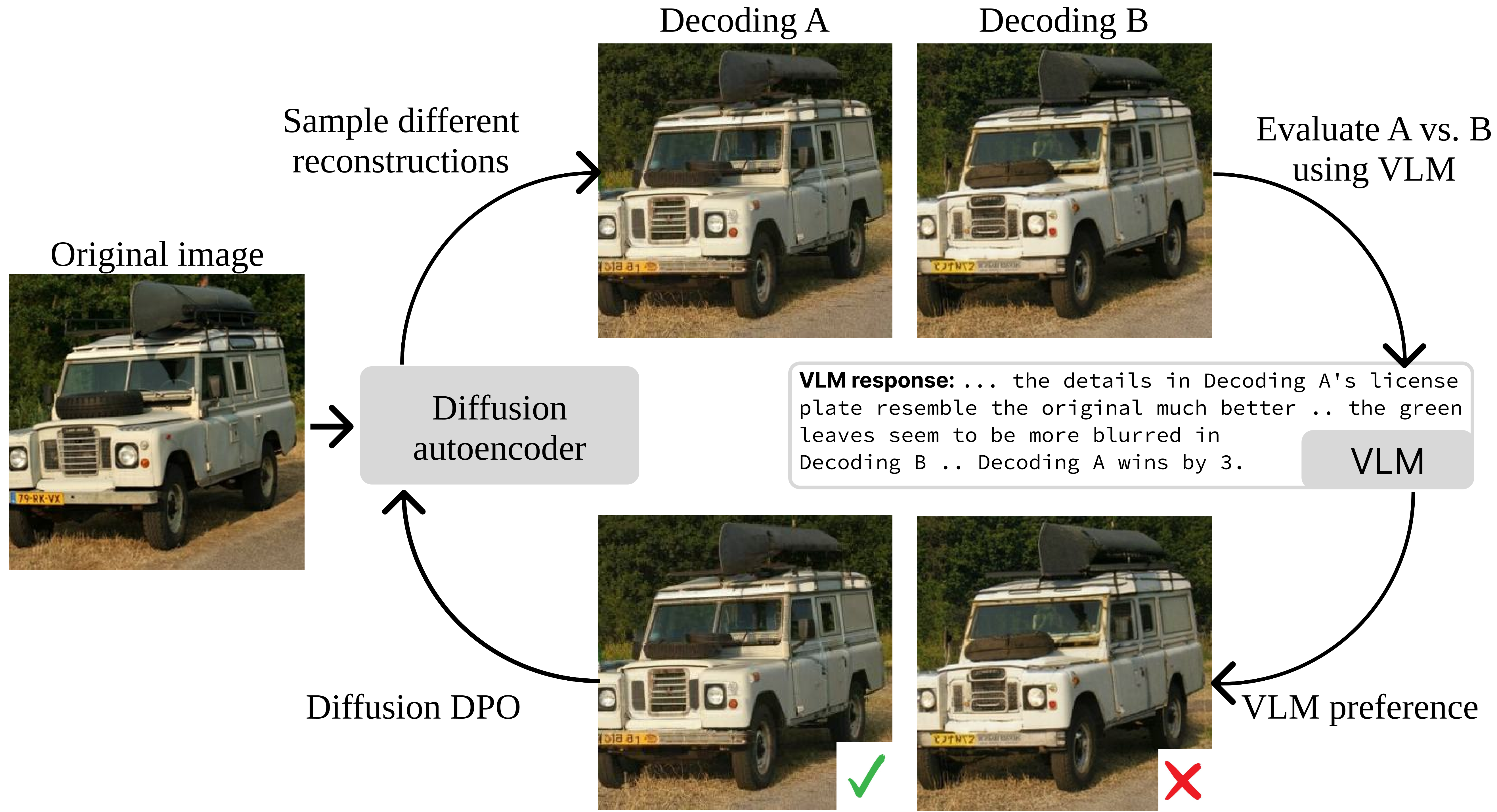
VLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression
Kyle Sargent, Ruiqi Gao, Philipp Henzler, Charles Herrmann, Aleksander Holynski, Li Fei-Fei, Jiajun Wu, Jason Zhang CVPR, 2026.
arxiv /
project page /
We propose Vision-Language Models for Image Compression (VLIC), a diffusion-based image compression system designed to be post-trained with binary VLM judgments.
Flow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization
We propose FlowMo, a transformer-based diffusion autoencoder that achieves a new state-of-the-art for image tokenization at multiple compression rates without using convolutions, adversarial losses, spatially-aligned two-dimensional latent codes, or distilling from other tokenizers. Our key insight is that FlowMo training should be broken into a mode-matching pre-training stage and a mode-seeking post-training stage.
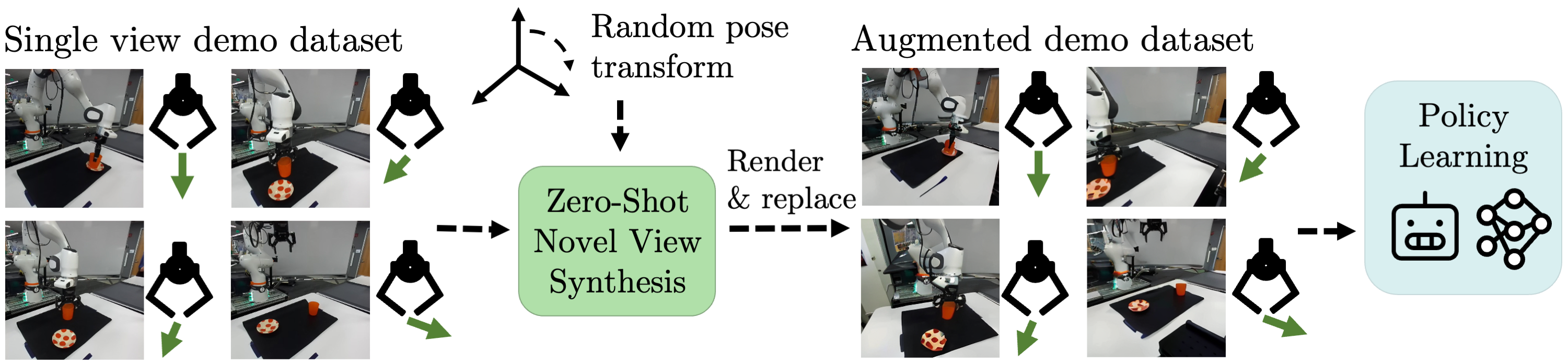
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
We empirically analyze view synthesis models as data augmentation for learning viewpoint-invariant policies from single-viewpoint demonstration data. On out-of-distribution camera viewpoints, our method outperforms baselines in both simulated and real-world manipulation tasks.
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, Carl Vondrick ECCV, 2024.
arxiv /
project page /
We finetune a video diffusion model for synthesizing large-angle novel viewpoints of dynamic scenes from a single monocular video. Our framework predicts RGB novel views of dynamic scenes, and we additionally extend it to show applications in semantic segmentation for driving scenes.
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing “Koven” Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, Jiajun Wu CVPR, 2024.
arxiv /
project page /
We train a 3D-aware diffusion model, ZeroNVS on a mixture of scene data sources that capture object-centric, indoor, and outdoor scenes. This enables zero-shot SDS distillation of 360-degree NeRF scenes from a single image. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting. We also use the MipNeRF-360 dataset as a benchmark for single-image NVS.
WonderJourney: Going from Anywhere to Everywhere
Hong-Xing “Koven” Yu, Haoyi Duan, Junhwa Hur, Kyle Sargent, Michael Rubinstein, William T. Freeman, Forrester Cole, Deqing Sun, Noah Snavely, Jiajun Wu, Charles Herrmann CVPR, 2024.
arxiv /
project page /
We introduce WonderJourney, a modularized framework for perpetual scene generation. W start at any user-provided location (by a text description or an image), and generate a journey through a long sequence of diverse yet coherently connected 3D scenes. We leverage an LLM to generate textual descriptions of the scenes in this journey, a text-driven point cloud generation pipeline to make a compelling and coherent sequence of 3D scenes, and a large VLM to verify the generated scenes. We show compelling, diverse visual results across various scene types and styles, forming imaginary wonderjourneys
NAVI: Category-Agnostic Image Collections with High-Quality 3D Shape and Pose Annotations
Varun Jampani*, Kevis-Kokitsi Maninis*, Andreas Engelhardt, Arjun Karpur, Karen Truong, Kyle Sargent, Stefan Popov, Andre Araujo, Ricardo Martin-Brualla, Kaushal Patel, Daniel Vlasic, Vittorio Ferrari, Ameesh Makadia, Ce Liu, Yuanzhen Li, Howard Zhou NeurIPS, 2023.
arxiv /
project page /
We propose “NAVI”: a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters.
VQ3D: Learning a 3D Generative Model on ImageNet
Kyle Sargent, Jing Yu Koh, Han Zhang, Huiwen Chang, Charles Herrmann, Pratul Srinivasan, Jiajun Wu, Deqing Sun ICCV, 2023. Oral Presentation. Best paper finalist.
arxiv /
project page /
We design a specialized tokenizer with a NeRF-based 3D aware decoder. The tokenizer allows for novel view synthesis from input images, and when an autoregressive generative model is trained over the tokenizer latent space, we also demonstrate generation of novel 3D-aware images.
We introduce self-supervised AutoFlow to handle real-world videos without ground truth labels, using self-supervised loss as the search metric.
Pyramid Adversarial Training Improves ViT Performance
Kyle Sargent,* Charles Herrmann,* Lu Jiang, Ramin Zabih, Huiwen Chang, Ce Liu, Dilip Krishnan, Deqing Sun (*equal contribution) CVPR, 2022. Oral presentation. Best paper finalist.
arxiv /
Aggressive data augmentation is a key component of the strong generalization capabilities of Vision Transformer (ViT). We propose “Pyramid Adversarial Training,” a strong adversarial augmentation which perturbs images at multiple scales during training. We achieve a new state of the art on ImageNet-C, ImageNet-Rendition, and ImageNet-Sketch using only our augmentation and the standard ViT-B/16 backbone.
SLIDE: Single Image 3D Photography with Soft Layering and Depth-aware Inpainting
V. Jampani*, H. Chang*, K. Sargent, A. Kar, R. Tucker, M. Krainin, D. Kaeser, W. T. Freeman, D. Salesin, B. Curless, C. Liu (*equal contribution) International Conference on Computer Vision, ICCV, 2021. Oral presentation. arxiv /
project page /
We design a unified system for novel view synthesis which leverages soft layering and depth-aware inpainting to achieve state-of-the-art results on multiple view synthesis datasets. We leverage the soft layering to incorporate matting, which allows the incorporation of intricate details to synthesized views.